阿里通义万相今日宣布了一项重大技术突破,正式向公众开源其创新的“首尾帧生视频模型”。该模型以惊人的140亿参数规模,在业界首次实现了如此大规模的开源首尾帧视频生成技术。
这款模型的核心功能在于,用户仅需提供一张起始图片和一张结束图片,它便能自动生成一段高清720p的视频,完美衔接首尾画面。这一技术的问世,无疑将为用户带来前所未有的视频生成体验,满足更加个性化和定制化的需求。
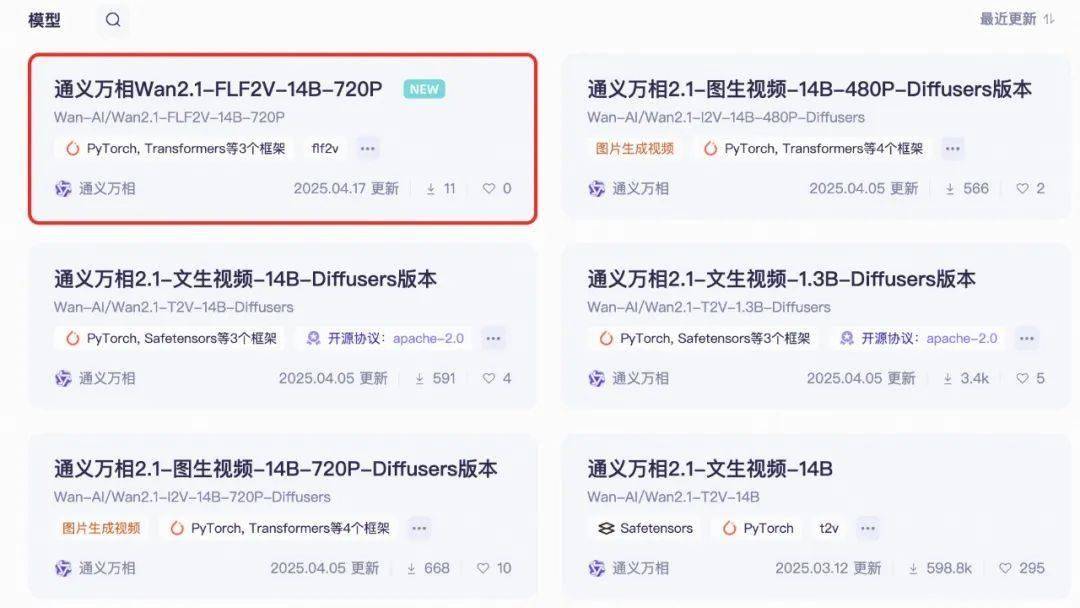
为了让更多用户能够轻松体验这一前沿技术,阿里通义万相提供了多种获取途径。用户可以直接访问通义万相官网,免费试用该模型;同时,该模型也已在Github、Hugging Face以及魔搭社区等平台上线,供开发者下载并进行本地部署和二次开发。
首尾帧生视频技术相较于文生视频和单图生视频,具有更高的可控性。然而,这类模型的训练难度也相应提升。为了确保生成的视频内容既与用户输入的两张图像保持一致,又能遵循用户的提示词指令,同时实现从首帧到尾帧的自然、流畅过渡,阿里通义万相团队在模型设计上下了不少功夫。
基于现有的Wan2.1文生视频基础模型架构,团队引入了额外的条件控制机制,从而实现了首尾帧视频生成的精准与流畅。在训练阶段,团队构建了专门用于首尾帧模式的训练数据,并采用了并行策略来优化文本与视频编码模块以及扩散变换模型模块,这不仅提升了模型的训练效率,还确保了高清视频生成的效果。
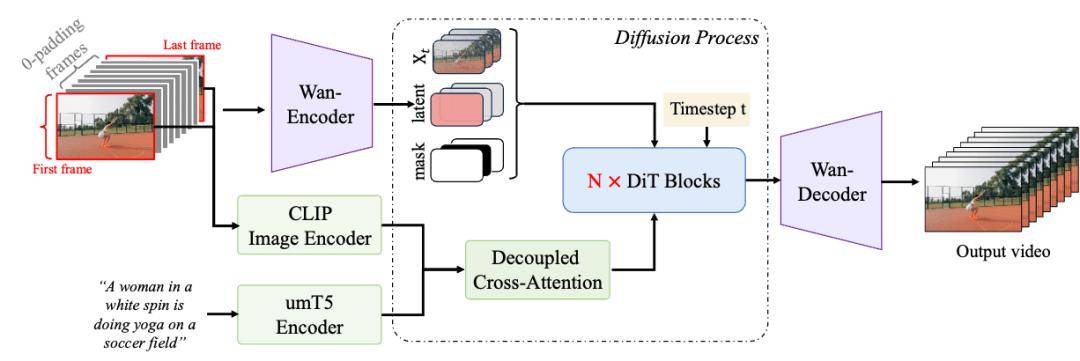
在推理阶段,面对有限的内存资源,团队采用了模型切分策略和序列并行策略,在确保推理效果不受影响的前提下,大幅缩短了推理时间,使得高清视频推理成为可能。
这款首尾帧生视频模型不仅技术先进,而且在功能上也有着诸多亮点。用户可以利用它完成更加复杂和个性化的视频生成任务,如实现同一主体的特效变化、不同场景的运镜控制等。例如,用户只需上传两张相同位置但不同时间段的外景图片,并输入一段提示词,模型便能生成一段展现四季交替或昼夜变化的延时摄影效果视频。用户还可以通过旋转、摇镜、推进等运镜控制,将两张不同画面的场景巧妙衔接,使视频在保持与预设图片一致性的同时,拥有更加丰富的镜头语言。
这一技术的推出,无疑将为视频创作领域带来一场革命性的变革。无论是专业视频制作者还是普通用户,都将能够利用这一技术轻松实现心中的创意,创作出独一无二的视频作品。